Parallelization¶
When running calculate_doublet_performance or calculate_doublet_performance_stochastic (described in more detail in deterministic doublet and stochastic_doublet) then each combination of input reservoir properties is an independent simulation, making this computation a good target for parallelization, where you use more hardware resources to run processes simultaneously to decrease the execution time.
Traditionally trying to parallelize code in python has been tricky and modules such as multiprocessing have been developed to handle this task, still a lot of custom code usually has to be developed to get the right setup for your specific problem.
pythermogis however uses xarray as its data framework which under the hood uses dask to run parallel operations. For more details on how xarray utilizes dask for easy parallelization we direct the reader to the following: Parallel Computing with Dask.
The framework has already been implemented in pythermogis, the user simply has to define the chunk_size parameter when calling either calculate_doublet_performance or calculate_doublet_performance_stochastic and then the doublet simulations will occur in parallel.
What is chunk size and how to determine the optimal value?¶
dask parallelization works by applying an operation (in this case simulate_doublet) across 'chunks' of input data in parallel.
As an example, say we wish to compute 1000 doublet simulations our smallest possible chunk_size would be 1, meaning that every simulation is sent as an independent job to a processor, while the largest chunk_size is 1000, meaning one job is sent to a processor and the simulations are run in series.
The first example would be inefficient as there is a computational cost to chunking and de-chunking the input and the output, while the second example is also inefficient as each simulation is run in series, the optimal chunk_size will be between these two values.
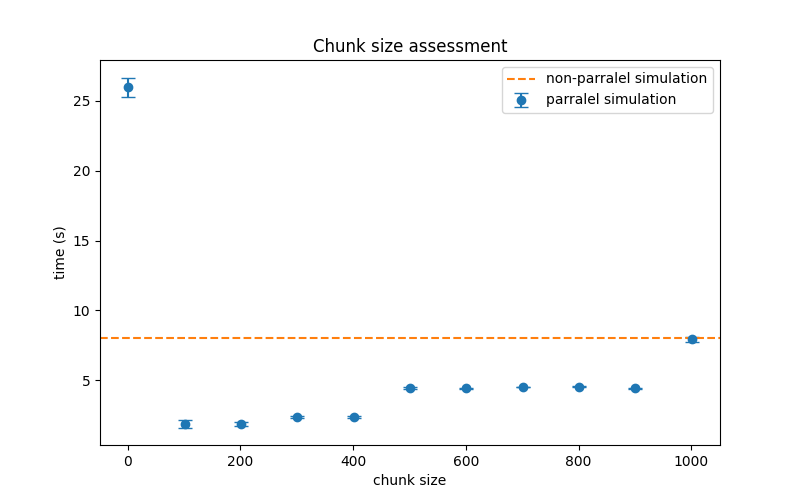
The following figure shows how different chunk sizes affects the overall compute time. It can be seen that the most efficient chunk size (for the hardware this example was run on) is by having 100-200 simulations per chunk.
To aid in assessing the optimal chunk size and to make the above figure pythermogis has a function you can run on your hardware: assess_optimal_chunk_size (see assess optimal chunk size for usage).